The problem I'm actually trying to solve comes from the world of using DNA to trace family history. You don't need to know that, but maybe it will save you wondering about my "for discussion" scenario, below.
I don't know if you can put a linked list into an ooBase database... but maybe this exploration of an analogue of a real world problem will exercise your ooBase gray cells, at least.
Suppose you had a big collection of strings of 9 digits.
Further suppose that each string USUALLY consists of....
1 2 3 4 5 6 7 8 9
... but often one or two digits are "wrong", e.g....
(the hyphens are just to make the "errors" stand out, and the usual sequence neat and obvious not out of any inherent logic, but just to make it easy to see differences from "the usual".)
1-8-3 4 5 6 7 8 9
1 2 3-1-5 6 7 8 9
... etc... and there can even be cases where there are more than one error...
1-8-3 4 5-1-7 8 9
Each string of digits is associated with a unique thingie... it could be anything, but for the sake of making the example concrete, let's pretend that we're doing quality control for a factory making camera lenses and the string of digits is the results of a 9 component test, where the test result for each component is a digit. (Note that the test scores aren't like school test scores... higher isn't better. For each test there is a (different) "right" answer. They just happen to go 1,2,3... so that "wrong" answers are easy to pick out when you look at the string of digits.) Each lens has a serial "number" consisting of letters, so we could make a database around the following table....
Table: Test results
Fields: Serial number of lens Results Sample data....
Serial Results
aaa 1234546789 aab 1234546789 aac 8234546789 aad 1234546789 aae 1574546719 aaf 1234546781
.... i.e. most of the lenses were fine, lenses aac and aaf each failed one test, and lens aae failed three. (If I've got that right! Do, please write in and complain if I've made mistakes in my descriptions!)
Now... if there were only 9 tests, this would be a perfectly reasonable way to go. A bit wasteful of disk space, but do-able.
What if there were a thousand tests... i.e. each "results" string was 1000 characters long, and failures were rare, and they could happen at any position in the string? AND failures ARE rare, but sometimes you get a batch of lenses all with the same failure.
It really doesn't make sense to store the same 1000 characters again and again with all of the flawless lenses.
(Digression: If this quality control problem was REALLY my goal, and even if there were really 1000 tests, the way to solve this might well be to have two tables.... one for the lenses and a summary of their results... the summary being the number of faults found. The other table would record the 1000 character strings, but just for the (rare) flawed lenses.)
I'm looking for.... (ah! At last we get to it!)... a way to give "names" to the different strings of digits. We don't need names for every string, i.e we don't need names for each of....
000000000 000000001 000000002 000000003 000000004 000000005 000000006 000000007 000000008 000000009 000000010.... etc
We just need a way to name each string the first time it appears, and to find whether a string as appeared each time we are presented with a new lens's test result.
We'll "name" 1234567899 "STa"
"ST" as a prefix that will go on all string names, "ST" for String Type.
"a" because it is the first letter in the alphabet, and we have to start somewhere, and we need a name for the "no faults" string.
Now part of our database of lens test results is....
Serial Results (using ST codes)
aaa STa aab STa aad STa...
... but we need "ST" names for the following lenses and their test results.
aac 8234546789 aae 1574546719 aaf 1234546781
For now, we will just assign them by hand:
Use For
STb 8234546789 STc 1574546719 STd 1234546781....
Which lets us finish re-doing the Serial/Results as ST Code table...
Serial Results
aaa STa aab STa aac STb aad STa aae STc aaf STd
Remember... to keep things simple, we're using a 9 digit test results string. The real problem behind this question has a 16,000 digit string.
So... a more compact table... but now we have problem of keeping track of the ST codes, and of assigning them. Because we don't know in advance what codes may arise, we need a process like this....
Look at test result just received.
Is it one we've seen before? If yes, use the old code If no, make up a new code
I have to add something new at this point. In the "lenses/ tests" example, you could check "is it one we've seen before" quite easily, by going down the list of ones seen before, checking the test result just received against the old test results. In the problem behind this question, it will not be possible to store the equivalent of the full string of test results. A different approach will be necessary. And I think it will be....
Let's take the results for lens "aac" as our example: 1574546719
Instead of storing that string, we will store a compact version of "Instead of the usual 2 in the second position, it had a 5."
I THINK the answer to my problem is to build a tree. Even for simple strings of only 9 digits it will... potentially... be vast. "the trick", I think, is to imagine the "shadow" of the possible tree, but "draw in" only the lines you need, drawing them in as the need arises, and assigning names to test results which arise WHEN they arise, just working through the alphabet... STa, STb, ... STy, STz, STaa, STab, STac...
For a mere TWO digit string, with only "1", "2" or "3" being possible values at any position, the tree would look like....
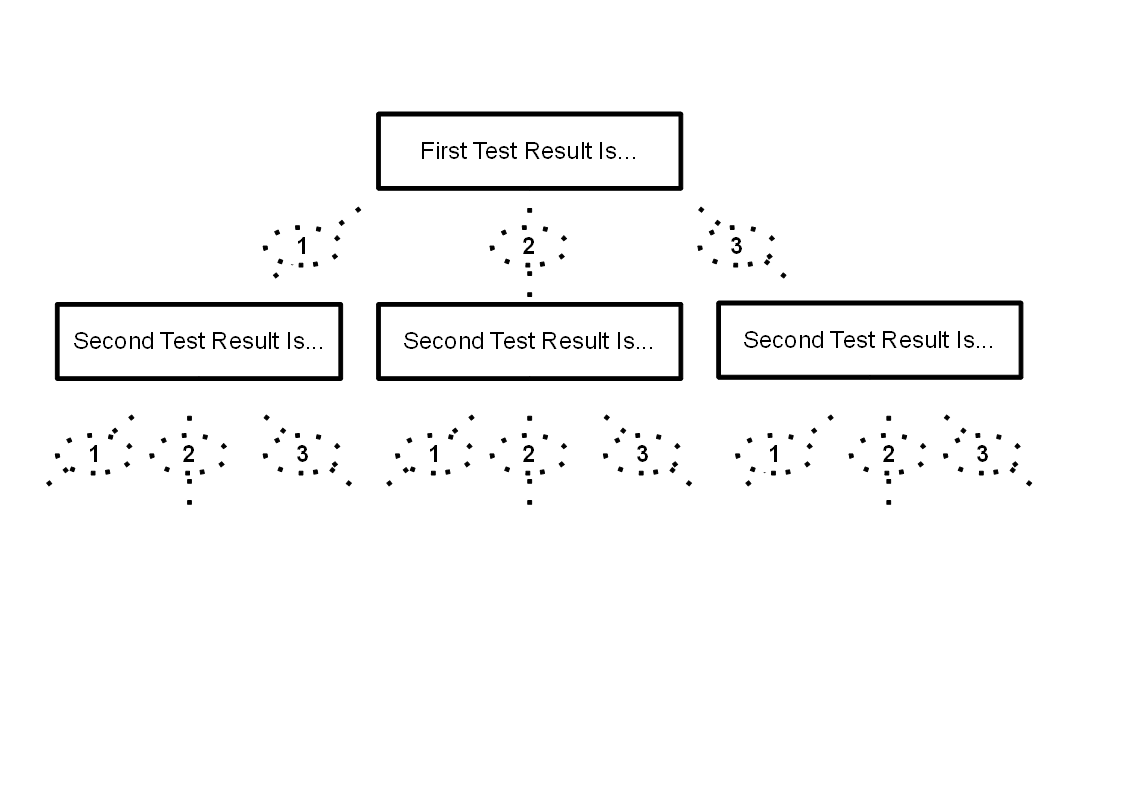
The dotted lines show all of the possible test result strings. So far, we have only drawn the "shadow" of the tree... no specific test result strings have been "seen" yet, no ST codes have been assigned.
On Day One, we go to the tree, and assign a code for the usual test result string, "12". We change the relevant dotted lines to solid lines, and put the next available ST code... which is "STa"... at the "leaf" position at the bottom of the "tree", giving us....
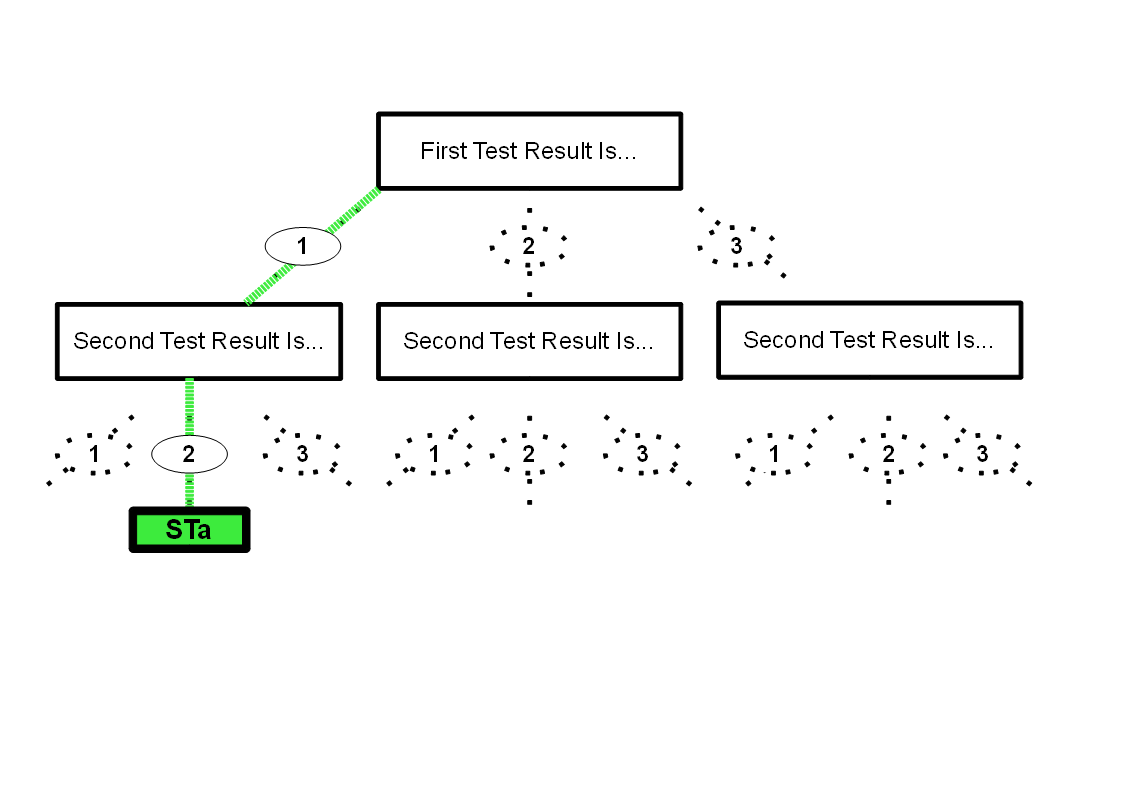
Now, any lens with a test result of "12" can be recorded as having had test result "STa". Not much of a saving, if you only have two tests! But if you have 1000 "tests".... (smile).
If you want to know what "STa" stands for, you go to the tree, find "STa" at the bottom, and work your way up through the "branches". This must be possible in any computer-held version of the tree!Solid
Now let's pretend that the next lens needing its test results recorded had result "31" (it failed both tests... unusual in our scenario, but it can still be accommodated). That test result gets given ST code "STb", and we alter the table, making it....
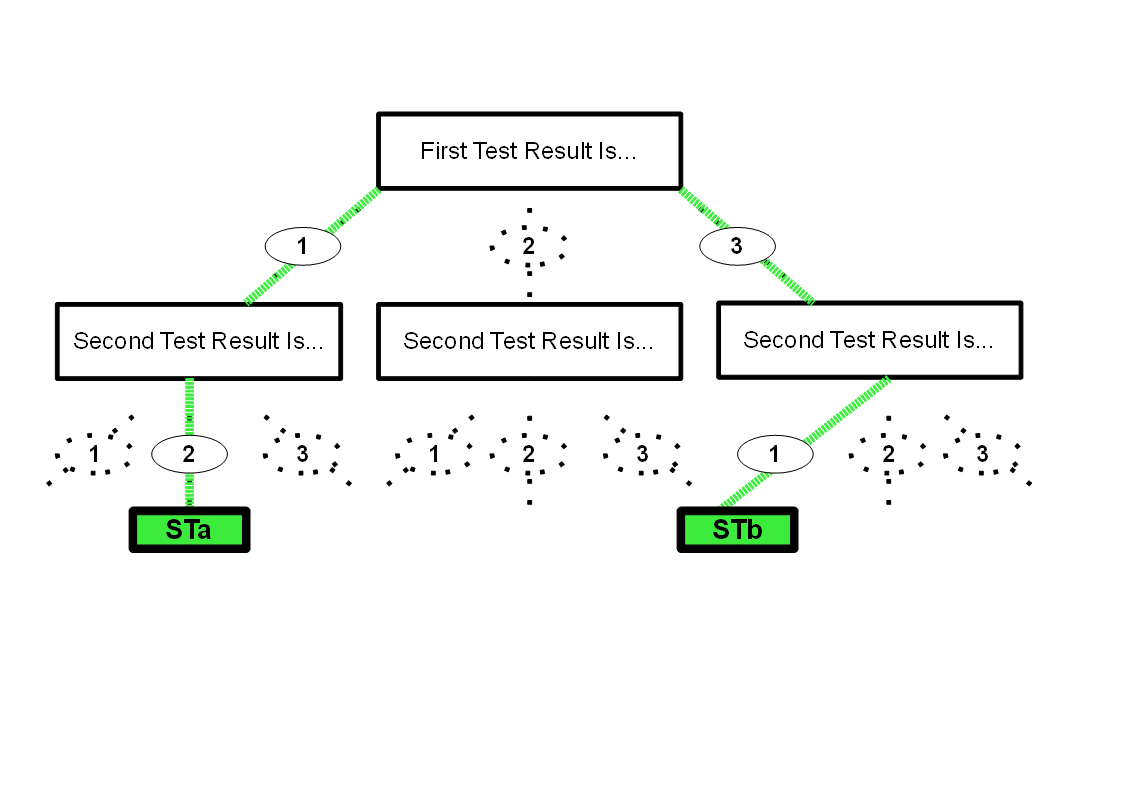
.... so that if many lenses later we get presented with another which also gave the results "31", we'll be able to see easily that we already have an ST code corresponding to "31". (That code being "STb".)
By the way: Those diagrams created with little hassle by someone with little experience of graphics or of "drawing" software, using the Open Office "Draw" module.
So! That's the back of the problem broken. We have a "do-able" system which can be extended as far as necessary, one that will not "run out of steam" no matter how many lenses we test, no matter how many different test result strings arise.
Of course, doing it ON PAPER would be a nightmare.
MY QUESTION (!).... Is there a way to put such a thing in a database?? Not the records of the ST code for each lens's test results... the "tree" with it's dotted and solid lines, and the ST codes at the tips of the branches?
I already realize that any tree can be converted to a binary tree (only two downward choices at any node) and that it probably(?) should be. In framing your answers, if you want to say "I'd use a binary tree, and it could be done like this...", you can skip over the bit about how to turn my tree into a binary tree. Alternatively, if you feel that a binary tree is NOT needed or desirable, just start by saying that, before going on to explain how the tree should be done. The data I am trying to fit into a tree does allow me to say that there will never be more than 13 paths down from any node. (There always be 13 POSSIBLE paths down from any node, though. Thirteen "dotted lines" in the "shadow" of the tree.) The good news is that, like the lens's test result tree, the meaning of each downward path is implicit in the structure of the tree. We are NOT, for instance, trying to build a tree with different questions at different levels, e.g. a tree for identifying things from their features, e.g. First question: Animal Vegetable Mineral? Second question, if Animal: Does it have legs? Etc. (Hey! Building an extensible version of THAT into a database would be fun, no??)
How does this relate to using DNA for family history hunting? There is something called mitochondrial DNA (mtDNA) in all of your cells. It came from your mother. Her's came from her mother. Etc.
DNA is made up of four "letters". There are about 16,000 letters in your mtDNA. The sequence of letters in every one of one individual's mtDNA strands is very, very likely to be EXACTLY identical. And the sequence of letters in every strand of EVERY person's mtDNA is going to be NEARLY the same as a sequence called the Cambridge Reference Sequence, the CRS. And the differences between your sequence and the CRS can be expressed along the lines of "instead of a 'c' at position 27, as in the CRS, he has a 'g'". (There's more to it than that... and less. (Only four letters arise is the good news, there are things other than simple substitutions is the bad news.))
The more closely the sequence of letters in two people's mtDNA matches, the better the chance that they share a reasonably recent maternal ancestor.
But all that DNA stuff is just for your curiosity, if it was peaked. All I need (or want!) to discuss here is how to build the tree to assign "ST" codes to different camera lens test result strings.
![]() Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org
Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org