Click here if you want to know more about the source and format of these pages.
This page is "browser friendly". Make your browser window as wide as you want it. The text will flow nicely for you. It is easier to read in a narrow window. With most browsers, pressing plus, minus or zero while the control key (ctrl) is held down will change the texts size. (Enlarge, reduce, restore to default, respectively.) (This is more fully explained, and there's another tip, at my Power Browsing page.)
Have you ever had to enter a registration key, or similar, into a computer? And been asked to type something like "abc0ldef5S"?
The "abc" and "def" parts are easy enough, and you can probably tell that the last two are "five" "ess"... but what about the "0l"? Is the circle an "oh", or a "zero"? Is the vertical line the digit "one" or a lower case "ell"?
Even though you can tell that the string ends "5S", it is very easy to misread those two characters.
And it is all so unnecessary. In this tutorial I will give you two functions which you can splice into your own programs. The first will take any string using only 0-9,a-z and A-Z (all inclusive), and "translate" the string into something of about the same length, but something containing no zeros, no "oh"s, no ones, no "ells". (A few other ambiguous characters are also filtered out.)
The second function will take the output of the first function, and turn it back into the original string.
I hope you find the functions useful. Even if you have no immediate need of the functions, you may find things present in the sourcecode which help you become a more capable programmer.
At the moment that's all I'm going to say here... but there are many notes explaining further, embedded in the source code... a very good place for this sort of thing.
Here is the code. You can also download a zip file with all of the files to work on PSD21 in Delphi. The .zip also includes the .exe file. It was developed in Delphi 4, but should work fine in other versions of Delphi, too.
unit psd21u1;
//See http://sheepdogguides.com/dt4v.htm for a discussion of the reason for,
// and logic behind the code present in this little "demomstrator" application.
(*Simple if somewhat contrived program to demonstrate two functions,
which are useful if incorporated, separately, in complementary programs.
The first, sUnAmbEncode() takes a string of characters, transforms it to
a second string. In the second, visually ambiguous characters, like
"0" (zero) and "O" ("Oh") are not present.
The second, sUnAmbDecode() converts the output of the first function
back into the original string.
The two were created for things like software registration keys, which
sometimes have to be typed by hand, but look like gibberish, so
context doesn't help, but whether you type, say, zero of "Oh" matters.
The whole thing also makes useful reading for some students of programming.
====
Using it: There will be two parties involved...
a) The end users of the strings
b) People needing to issue strings with ambiguous characters in the
transformed, ambiguous-character-less form.
c) The programmer using the functions
The first group won't need to know... or even be aware!... any of the details.
They will be told "type this... ", and that's all they have to accompish.
Issuers of strings will need a little app into which they type the original
string, and from which they get the better-to-issue-to-users string.
The program generating the "better" string will need to be set to use rules
which are those being used by the program the string is being typed\
into. Unless the programmer has tweaked things (see next), it is likely
that only one "set of settings" will be "underfoot", so all of this,
in those circumstances, can be ignored!
Programmers may not need to look to closely at the details. The details
are provided primarily to enable programmers to tweak what is presented
here. The main "tweaking" that a programmer can do is to change the "Escape
character" (see below), or change the set of characters excluded from the
output. The first character of a lacking-ambiguous-characters string (which
should also be the last character of the string) is a "code" to say what
scheme of escape-character-in-use and not-allowed-characters was used.
The first character will be a lower case "x" for the scheme used in the
untweaked version of PSD21.
====
Please note: This program can handle only strings containing nothing other
than characters represented by 48-57, 65-90, 97-122... inclusive. (Numbers
are decimal.) I.e: the characters 0-9, A-Z, and a-z. This restriction,
not important in many instances, avoids the problems of...
non-printing characters,
the "invisibility" and "uncountablility" of space(s)
... but more importantly, it makes creating codes for "Escaped out
characters easy. If the full gamut of 0-255 is attempted, the
escaping out scheme has to be much more complex.
====
How does the scheme work?
Pretend you want to transform....
jkl0PKM
.... and that you are only concerned with changing the l and the 0 to
something less ambiguous. (As it happens, not that it matters for our
needs here, I typed a lower case L and a zero there.)
Most of that would remain unchanged, yielding...
jk{something for the l}{something for the 0}PKM
(The system IS case sensitive)
If you were paying attention earlier, you will know that the resulting string
will have a letter at the start to indicate the coding rules. For the
"standard" rules, that letter will be an x. The "coding rules" letter is
also added to the end of the lacking-ambiguous-characters string, to
give users a second chance to obtain this critical character, in case
what they are copying from isn't fully legible. Thus the string would be...
xjk{something for the l}{something for the 0}PKMx
The letter to indicate the coding scheme can be any letter that isn't being
eschewed as ambiguous and isn't being used as the "escape character",
(See below). It also needs to be a letter which hasn't already been
used for a previously defined coding scheme.
To include "something for the l" and "something for the 0" in the
lacking-ambiguous-characters string, we turn to an old trick. We set aside
a character, called "the escape character", and use it ONLY to say,
"Ignore me, expect as an indication that the next character, whatever
it may be, should be treaded differently that it would have been treated
if it weren't preceded by me." Inside PSD21 there a mechanism which,
unless you've tweaked the coding scheme, causes any zero to be turned
into two characters: A "k" (The standard scheme escape character) and
something else.... a (EDIT... FILL IN RIGHT CHAR), as it happens, but there
was not simple way for me to work that out by hand... I just encoded a
string and looked to see what was produced for a zero.
To repeat what I just tried to say: Each character deemed ambiguous by the
coding scheme in effect is replaced by two characters. The first is
the escape character (so that the decoding program can identify the
cases where two characters need to be boiled down to one), and a second
character, which, indirectly, "says" which (ambiguous) character the
two (not ambiguous) characters stand for.
"Escape character": A not-ambiguous character which is reserved for marking,
in the lacking-ambiguous-character strings produced by PSD21's "encode"
function ("sUnAmbEncode()"), the presence of a pair of characters to be
"boiled down" to a single, ambiguous, character. The "boiling down"
takes place inside the computer, so the re-emergence of an ambiguous
character doesn't matter, as they are only ambiguous to human eyes.
"Coding scheme": Programmers can choose the character they want set aside
as the escape character, and the characters they want excluded from the
lacking-ambiguous-characters strings produced by sUnAmbEncode().
The "coding scheme" is merely the "settings" those choices imply.
*)
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs,
StdCtrls, ExtCtrls;
const ver='14Apr12b';
//Program thought about for YEARS... started 11Apr12... along the road
// to a Finally Do It Right system of ini files and SliceDice.
// (Of course, after spending a day, I realized it wasn't really
// relevant to those, but by then I was well startedunit psd21u1;
type
TPSD21f1 = class(TForm)
Memo1: TMemo;
eAmbigOrig: TEdit;
buToLessAmbig: TButton;
buToOriginal: TButton;
laAmbidOrig: TLabel;
laLessAmib: TLabel;
laAmbigFrmLessAmbig: TLabel;
laCheckMatch: TLabel;
eLessAmbig: TEdit;
buQuit: TButton;
eOrigFrmLessAmbig: TEdit;
procedure eAmbigOrigChange(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure buToLessAmbigClick(Sender: TObject);
procedure buToOriginalClick(Sender: TObject);
procedure buQuitClick(Sender: TObject);
procedure eAmbigOrigKeyPress(Sender: TObject; var Key: Char);
private
{ Private declarations }
function sUnAmbEncode(sToFix:string):string;
function sUnAmbDecode(sToDecode:string):string;
public
{ Public declarations }
end;
var
PSD21f1: TPSD21f1;
implementation
{$R *.DFM}
procedure TPSD21f1.FormCreate(Sender: TObject);
begin
eAmbigOrig.text:='';
caption:='PSD21- Convert strings, to remove visually ambiguous '+
'characters. Version: '+ver;
end;//.. of formcreate
procedure TPSD21f1.eAmbigOrigChange(Sender: TObject);
begin
laCheckMatch.font.color:=clWindow;
laCheckMatch.caption:='- - -';
end;
procedure TPSD21f1.buToOriginalClick(Sender: TObject);
begin
eOrigFrmLessAmbig.text:=sUnAmbDecode(eLessAmbig.text);
if eOrigFrmLessAmbig.text=eAmbigOrig.text then begin
laCheckMatch.caption:='Both encode and decode seem to be working';
laCheckMatch.font.color:=clGreen;
end//no ; here
else begin
laCheckMatch.caption:='There is a problem with encode and/or decode';
laCheckMatch.font.color:=clRed;
end;
end;
procedure TPSD21f1.buToLessAmbigClick(Sender: TObject);
begin
eLessAmbig.text:=sUnAmbEncode(eAmbigOrig.text);
end;
procedure TPSD21f1.buQuitClick(Sender: TObject);
begin
application.terminate;
end;
procedure TPSD21f1.eAmbigOrigKeyPress(Sender: TObject; var Key: Char);
begin
if Key=char(13) then eLessAmbig.text:=sUnAmbEncode(eAmbigOrig.text);
end;
//----------------------------------------------------------------
//=================== sUnAmbEncode() ==================
//================ To be exported to "target" apps ===============
//The name, by the way... UnAmbEncode... derives from....
//"A way to ENcode strings of letters which start, in the plaintext,
//with visually ambiguous characters. The output contains only
//UNAMBiguous characters. (Don't misread the "Un" as indicating
//that this function DE-CODES a string created by unambigENcode.
function TPSD21f1.sUnAmbEncode(sToFix:string):string;
var sTmp,sBuildResult,sEscChar,sAllowed, sNotAllowed,
sEscapeCharPlusNotAllowed,sCodeSchemeID:string;
c1:integer;
boOKstring:boolean;
(*The scheme of encoding is as follows....
Unambiguous characters just pass through to the output unchanged.
Let's say the whole character set is... jkLmnOpqr
(In that I've used upper case letters for ones to be deemed ambiguous.)
So, at first, we would say that the following pass through unchanged:
jkmnpqr
From them, one is removed; it will be the "escape character". For this example,
we'll use k as the escape character, which I will show as upper case from now
on, to emphasize it too is "special". (In the actual implementation of the
system, "k" and "K" are treated as separate, unrelated characters.)
So our remaining non-special characters are: jmnpgr
They are held in the string called sAllowed. Note that sAllowed does not
include the escape character.
The not allowed characters, including the escape character, are held in
sEscPlusNotAllowed, which, in our simple example, is KLO
To encode a NOT allowed character, you put two characters in the output string:
i) The escape character
ii) The nth character of sAllowed, counting from zero, where "n" is the position
in sEscPlusNotAllowed of the not allowed character you wish to encode.
Thus, in the "world" of our limited example....
jnLOpKm would encode as....
j - n - KM - KN - p KJ - m
(without the spaces and hyphens)
In addition to the above, a letter to indicate the coding scheme is added
to the string, both at the start, and at the end. Thus, if the above were
being coded under coding scheme "p", the full result would be....
pjnKMKNpKJmp
Remember: letter case has been used in this example to help make the pairs
of characters, each starting with the escape character, stand out. In the
scheme as actually used, there is "no connection" between, say, K and k, and
both can appear in the output of sUnAmbEncode()
(without the spaces and hyphens)
*)
begin
(*It may seem odd to have some of what you see here inside, and local to,
the function. Those things were put here to simplify "exporting" the
function into other programs.
Be careful that essential things, particularly the values in sNotAllowed,
sEscChar, and sCodeSchemeID are consistent between this function and
any instances of sUnAmbDecode() present in complementary programs.
*)
(*Here begins definition of "standard" code scheme.
For different code scheme, tweak JUST these three lines.
Be sure that GLOBALLY, the letter assigned to sCodeSchemeID
is not used for more than one scheme.*)
sNotAllowed:='0oO1lLiI5sS2zZ';
sEscChar:='x';
sCodeSchemeID:='p';
(*BE CAREFUL not to allow multiple code schemes with the same
code scheme ID. For TKB, the ultimate authority is the listing
presented in DT4v.htm... NOT the current latest m/r copy of
PSD21... although that TOO should have a complete list of allowed
code schemes.*)
//End "define code scheme"
(*Test code scheme valid....
(Compliance with some of these rules is ensured by the machine
generation of some strings, which is just about to happen.)
Only chars from 0-9, a-z, A-Z included... unless you take GREAT care
(primary requirement: "NotAllowed"(plus 1) must be < "Allowed")
Allowing spaces in the string-with-ambiguous-characters adds special
risks.
Check that escape char is not also in either of other strings
Check that no char in both Allowed and NotAllowed, and that between
them, all possible characters are provided for.
*)
sEscapeCharPlusNotAllowed:=sEscChar+sNotAllowed;
//Build sAllowed. Start with...
sAllowed:='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'+
'abcdefghijklmnopqrstuvwxyz';
// and take out the one assigned as Escape character, and the ones in sNotAllowed...
sTmp:='';
for c1:=1 to length(sAllowed) do begin
if pos(sAllowed[c1],sEscapeCharPlusNotAllowed)=0
then sTmp:=sTmp+sAllowed[c1];//No "else" clause for this
end;//for....
sAllowed:=sTmp;
//showmessage(sAllowed);//for debug, when tinkering with coding schemes
//Provide tests, if needed, to ensure that no character
// appears both in sNotAllowed and sAllowed, and that sEscChar
// not in either. If basic automatic generation of sAllowed used,
// all you need test is that sEscChar is not in sNotAllowed
if pos(sEscChar,sNotAllowed)<>0 then begin
showmessage('You are attempting impossible coding scheme. '+
'sNotAllowed must not contain sEscChar. Program will shut down.');
application.terminate;
end;//of "then". No else here.
//At this point, I had intended to build a string I would have called
// sEncode. However, sAllowed holds what would have gone into sEncode...
// the characters which are allowed in the output, i.e. the universe
// of characters MINUS the character set aside as the escape character,
// and minus the disallowed (because ambiguous, e.g. zero and "oh")
// characters. So! Where you see "sAllowed" after this, it is probably
// being used as the lookup table for encoding disallowed characters.
//(end of "It may seem odd to have...")
//Next, check to see that string to be encoded only has characters which
//are either allowed as not ambiguous, or provided for in the list of characters
//which will be converted to two character ("escape char" plus one)...
//The following crude, and slow... but they are trumped, in this instance,
// by how clear the code can be, if done thus...
boOKstring:=true;
for c1:=1 to length(sToFix) do
if (pos(sToFix[c1],sAllowed)=0)
and (pos(sToFix[c1],sEscapeCharPlusNotAllowed)=0) then boOKstring:=false;
// no "end" for this "for", as there was no "begin"
if boOKstring then begin
sBuildResult:='';
for c1:=1 to length(sToFix) do begin
if pos(sToFix[c1],sEscapeCharPlusNotAllowed)<>0 then begin
//Remember... see above... sAllowed in the next line is being
// used as a lookup table to find the right character to
// combine with the escape char to build a unit of two
// unambiguous characters to stand, in the output string, for
// one ambiguous character found in the input string.
sBuildResult:=sBuildResult+
sEscChar+sAllowed[pos(sToFix[c1],sEscapeCharPlusNotAllowed)];
end//no ; here.. end of then begin..
else begin
sBuildResult:=sBuildResult+sToFix[c1];
end;//of else
end;//for
result:=sCodeSchemeID+sBuildResult+sCodeSchemeID;
end//no ; here End of "boOKstring was true"
else begin
result:=sCodeSchemeID+
'THERE WERE INVALID CHARACTERS IN THE INPUT STRING. SORRY!'+sCodeSchemeID;
end//End of "boOKstring" "else"... i.e., it was not true...
end; // of function sUnAmbEncode()
//----------------------------------------------------------------
//=================== sUnAmbDecode() ==================
//================ To be exported to "target" apps ===============
function TPSD21f1.sUnAmbDecode(sToDecode:string):string;
var sTmp,sNext,sEscChar,sAllowed,sNotAllowed,sCodeSchemeID,
sEscapeCharPlusNotAllowed,sBuildResult:string;
cDeCodesAs:char;
c1,cTarget:integer;
boOk:boolean;
function chProcessEscPlusCodeChar(var c1:integer):char;//SR of sUnAmbDecode
(*On entry to this, the escape character has already been read from
the string that is being decoded. But the pointer to where we've got to
in the string has not yet been advanced. (Note that c1 is passed to the
subroutine as a VAR parameter, which is essential or else the calling
code won't "learn about" what has been done to c1 inside this subroutine.*)
begin
inc(c1);//To "throw away" escape char
sNext:=sToDecode[c1];
inc(c1);//Move past the escaped char, to be ready to read next
result:=sEscapeCharPlusNotAllowed[pos(sToDecode[c1-1],sAllowed)];
//result:=sEscapeCharPlusNotAllowed[2];
end;//chProcessEscPlusCodeChar
begin
(*It may seem odd to have some of what you see here inside, and local to,
the function. Those things were put here to simplify "exporting" the
function into other programs.
Be careful that essential things, particularly the values in sNotAllowed,
sEscChar, and sCodeSchemeID are consistent between this function and
any instances of sUnAmbDecode() present in complementary programs.
*)
(*Here begins definition of "standard" code scheme.
For different code scheme, tweak JUST these three lines.
Be sure that GLOBALLY, the letter assigned to sCodeSchemeID
is not used for more than one scheme.*)
sNotAllowed:='0oO1lLiI5sS2zZ';
sEscChar:='x';
sCodeSchemeID:='p';
//End "define code scheme"
(*Test code scheme valid....
(Compliance with some of these rules is ensured by the machine
generation of some strings, which is just about to happen.)
Only chars from 0-9, a-z, A-Z included... unless you take GREAT care
(primary requirement: "NotAllowed"(plus 1) must be < "Allowed")
Allowing spaces in the string-with-ambiguous-characters adds special
risks.
Check that escape char is not also in either of other strings
Check that no char in both Allowed and NotAllowed, and that between
them, all possible characters are provided for.
*)
sEscapeCharPlusNotAllowed:=sEscChar+sNotAllowed;
//Build sAllowed. Start with...
sAllowed:='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'+
'abcdefghijklmnopqrstuvwxyz';
// and take out the one assigned as Escape character, and the ones in sNotAllowed...
sTmp:='';
for c1:=1 to length(sAllowed) do begin
if pos(sAllowed[c1],sEscapeCharPlusNotAllowed)=0
then sTmp:=sTmp+sAllowed[c1];//No "else" clause for this
end;//for....
sAllowed:=sTmp;
//showmessage(sAllowed);//for debug, when tinkering with coding schemes
//Provide tests, if needed, to ensure that no character
// appears both in sNotAllowed and sAllowed, and that sEscChar
// not in either. If basic automatic generation of sAllowed used,
// all you need test is that sEscChar is not in sNotAllowed
if pos(sEscChar,sNotAllowed)<>0 then begin
showmessage('You are attempting impossible coding scheme. '+
'sNotAllowed must not contain sEscChar. Program will shut down.');
application.terminate;
end;//of "then". No else here.
//Build decode string....
//(end "Odd...")
//Check that sCodeScheme char is at start and end of sToDecode. Be sure they
//are the same as one another, AND the right letter...
boOk:=true;
if sToDecode[1]<>'p'then boOk:=false;//'p' would be changed, if you are encoding
//with a different code scheme.
if sToDecode[length(sToDecode)]<>'p'then boOk:=false;
//now, strip off the "code scheme" ID letter from each end of string
sCodeSchemeID:=sToDecode[1];
sToDecode:=copy(sToDecode,2,length(sToDecode)-2);
//Next, check to see that string to be decoded only has characters which
//are either allowed as not ambiguous, or the "escape char"...
//The following crude, and slow... but they are trumped, in this instance,
// by how clear the code can be, if done thus...
boOK:=true;
for c1:=1 to length(sToDecode) do
if (pos(sToDecode[c1],sAllowed)=0)
and (sToDecode[c1]<>sEscChar) then boOK:=false;
// no "end" for this "for", as there was no "begin"
if boOK then begin //Big block "A"
sBuildResult:='';
cTarget:=length(sToDecode)+1;
c1:=1;
while c1<cTarget do begin
if pos(sToDecode[c1],sEscapeCharPlusNotAllowed)=0 then begin
sBuildResult:=sBuildResult+sToDecode[c1];
inc(c1);
end//no ; here.. end of "then begin.."
else begin //deal with a case of (escape char + second letter),
//standing for one of the ambiguous characters
cDecodesAs:=chProcessEscPlusCodeChar(c1);
sBuildResult:=sBuildResult+cDecodesAs;
end;//of else
end;//do of "while c1<256..."
result:=sBuildResult;
end//no ; here. End of "then..." Big Block "A"
else
begin
result:='Sorry... characters in input are unacceptable to coding '+
'scheme in use, code scheme ID: '+sCodeSchemeID;
end;//end of "else" to go with Big Block "A" "then" block
end;
end.
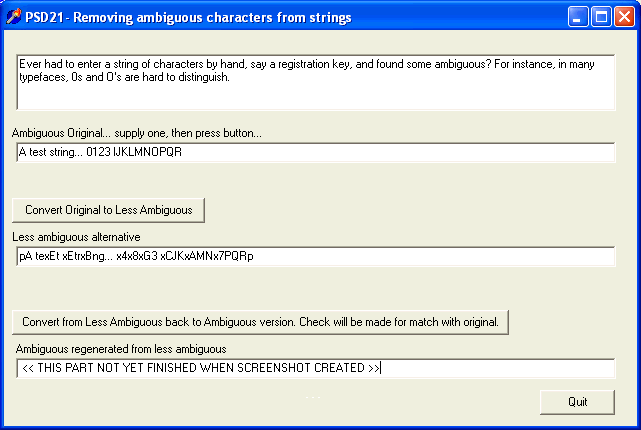
For the sake of a pretty picture, here's what the demonstrator application developed in this tutorial looks like. The "Ever had..." a the top just introduces what the application is for. A user entered the "A test string...", and then clicked the "Convert Original..." button. After that, the text "pA texEt xE..." appeared in the third black- text- on- white- background section. This was the test string converted to a string without ambiguous charaters. (The "s" in "test" having, for instance, been converted to "xE". ("s", poorly printed, can look like "5".) When the application is finished, which it wasn't when the screenshot was produced, the second button ("Convert from...") will re-convert the converted string back into the original plain text, complete with ambiguous characters.
|
|
If you visit 1&1's site from here, it helps me. They host my website, and I wouldn't put this link up for them if I wasn't happy with their service. They offer things for the beginner and the corporation.![]()
![]() Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org
Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org
....... P a g e . . . E n d s .....