 Bookmark this on Delicious
Bookmark this on Delicious
 Recommend toStumbleUpon
Recommend toStumbleUpon
At some point after 1958, the cryptographer Howard T Oakley wrote a paper called "An application of Bayes' Theorem to The solution of Transposition Ciphers".
I barely understand the words in it, let alone what they are saying, but I thought that the idea of the following tables, which accompanied the paper might be of interest.
They may even be of use, if you are setting about trying to devise a way to decipher things written in something other than English. For a frequency tables for letters in English and other texts, use the link, which will take you to Wikipedia's page, or the one cited later for a fancier table. Read on, if you want thoughts on frequency tables, or tables for some other languages.
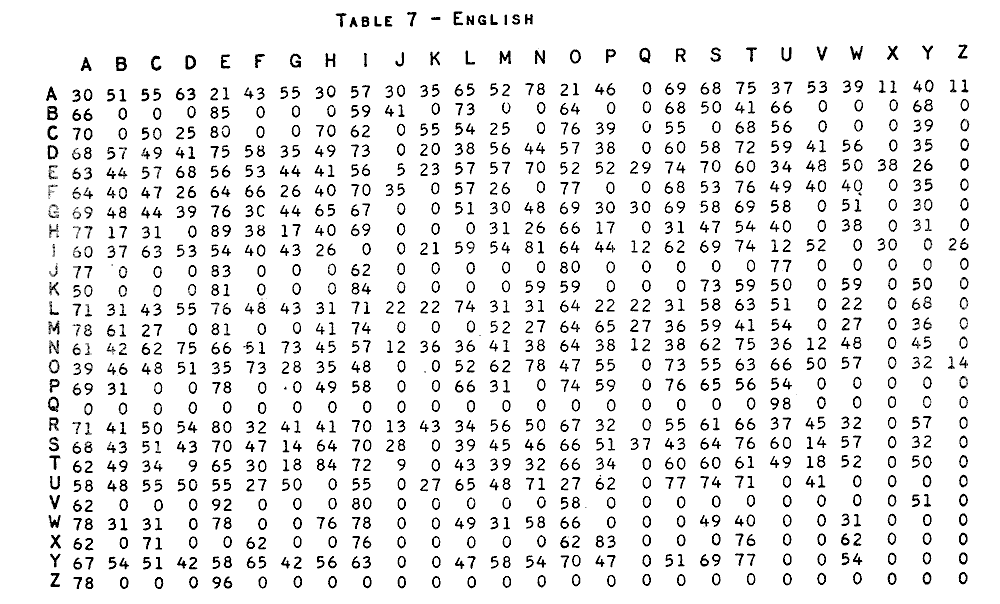
The following tells us something... we'll come back to that... about the of frequencies of letters in English.
You can treat the question of "What does the table tell us?" as an exercise for your "code breaking" skills... and if you want to be a code maker, few things will make you stronger, faster, than "going to the Dark Side", and trying to think, "How would I break that?"
So. The table has something to do with frequencies of letters in English. Obviously, not the frequencies of single letters. Pairs of letters? How do we read the table?
Read no further until you have thoroughly digested the material above, attempted to deduce how you read the table.
... The answer is just a little farther down the page now...
Look at the row with "Q" at the left hand end. Every column, other than the one with "U" at the top has a zero in it. Ah! Q is (almost) always followed by a U in English. I hope you now see how to read this table of the frequency of letter pairs in English?
Look at the row for B. Apparently, B is rarely (if every) followed by B, C, F, G, H... W, X or Z in English.
And we can "decode" something else: This table isn't using percents. Otherwise, all of the numbers in the "B" row would add up to 100, wouldn't they?
But I believe you can use the table at least to the extent of saying "big number, frequent occurrence".
(P.S. After about two hours of putting this page together, for you, I discovered that tables 1-6 (which I have not presented here for you) do seem to be giving the frequencies of pairs as percents, and would have been the tables to capture for you, instead of 7-12. Sorry! But most of the two hours was on creating the images, and I'm not repeating that work. Just remember: Big number, common pair. A little bonus, by way of apology: Did you ever notice the following? I hadn't. Not only is Q virtually always followed by a U, but that Z is mostly followed by an E (80%), and otherwise an A (20%). Oddities like this are immensely helpful in cryptanalysis.)
I do not much understand, or expect you to wrestle too much with the following. It is the opening to Oakley's essay. Here it is, just in case something interests you...

What is, in the above, "Gaines (4)" or "Eyraud (3)"? Those are just references to material Oakley drew upon...

Just in case they are fun, I'm now going to give you some of the other tables from the essay. The units used in the tables here are explained(?!) as follows...

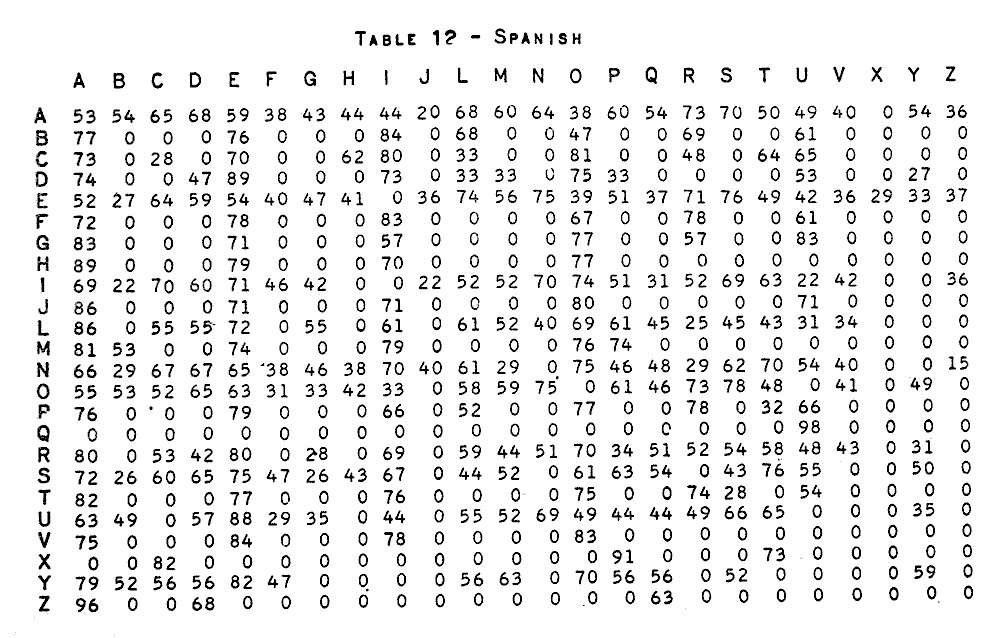
The really obsessive among us will have fun seeing how the Italian and Spanish tables are similar, and somewhat similar to the table for English "sequent plaintext letters", as the essay calls them. Letter pairs, I might have said!
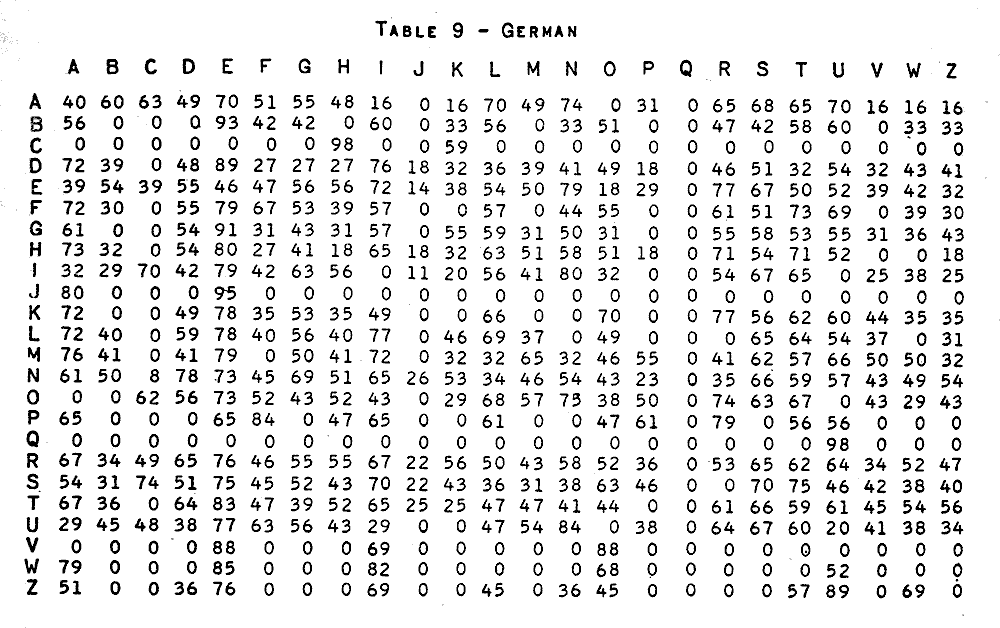
The German table comes next, for contrast. And then there's the Russian, which highlights the fact that not every language you might want to encrypt uses the "normal", "Latin" alphabet!


Lastly, the following was a section in the paper which may or may not interest you. (Note that the tables on this web page are not in the range discussed below.)

Although of little use for any serious cryptographic need, a simple substitution cipher can be fun in the way that jigsaws and crosswords are fun. And if you are learning computer programming, you can have fun writing programs to encrypt text, and other programs to "administer" the breaking of text encrypted that way.
Once you've made a few informed guesses about what character might stand for "e", etc, you can then look deeper into the patterns in the encrypted text.
The letter following an e is not, unfortunately for us, as "regular" as the letter following a q. Also, the frequencies in a small sample (the text you are decrypting) won't exactly match the frequencies in a larger sample. But all is not lost!
From the lovely letter frequency table provided by the University of Illinois Mathematics Department, we can see that the letter following an e is likely to be an r, a d, an n or an a. And, equally useful... if you use it... unlikely to be in the set j,k,q,u or z.
But that's not all we can do, even with only a guess as to which character stands for "e". Think a bit. Scroll down when ready for the answer....
... The answer is just a little farther down the page now...
What about the letter before the e? The table (read the column under the e) tells us that h is highly likely... even in a small sample, I would guess that the h is detectable, with r also a strong candidate. After that, it is less easy. l. m. n, s, t and v are all candidates.
In the previous paragraph, leaving out the references to single letters, a quick scan suggests that e was preceded by h 6 times. Sadly, it was also preceded by t 6 times, and l 6 times. But after that comes r at only 3 times, and five other letters even less frequently.
There's a snag in using the tables, unless they were compiled taking that snag into account.
If you look, say, at the frequency of h's before e's in English words, you get one number. But when breaking encryption, we don't usually know where the words start, so we would prefer tables of the frequency of letter pairs in English text.
In "The cat sat on the mat", the second sort of table would add a count for each of the following, wouldn't it? "ec", "ts", "to". "nt" and "em".
That h comes before e very frequently is less surprising when you remember the fact that "the" is a very common word. Patterns like this are the basis of many "tricks" for breaking encryptions, be they simple substitution ciphers, or more complex techniques.
We've looked briefly at some tables of the frequencies of letter pairs in various languages. Such tables help cryptanalysts.
If the code you are trying to break allows you to know where words start and end, that's a huge gift. (If you are making a cipher, don't give that away!) Also tables of common word associations. (E.g., "the" often follows "of".)
Cryptanalysts also have tables of the most common letter, pairs of letters, tri-glyphs, at the start (and end) of words (and sentences).
They have tables of common (and, almost as useful, uncommon) tri-glyphs.
If you wanted to have some fun... I'm not sure what else it would be "good" for, you might try writing a computer program to "make up" text in English or any other language, using these tables of common letter associations. AI, here we come...
That's about it, for this page.
May I invite you to return to, or go to, the main Flat Earth Academy page on cryptography, ciphers and codes? If you came here by clicking on the link there, you need only close this tab or window... the main page is underneath this.
Have you heard of Flattr? Great new idea to make it easy for you to send small thank you$ to people who provide Good Stuff on the web. If you want to send $$erious thank yous, there are better ways, but for a small "tip" here and there, Flattr ticks a lot of boxes which no one else has found a way to do yet. Please at least check out my introduction to Flattr, if you haven't heard of it? "No obligation", as they say!
Letter frequencies and code breaking- Flat Earth Academy page.Search across all my sites with the Google search button at the top of the page the link will take you to.
Or...
Search just this site without using forms,
Or... again to search just this site, use...
The search engine merely looks for the words you type, so....
*! Spell them properly !*
Don't bother with "How do I get rich?" That will merely return pages with "how", "do", "I", "get" and "rich".
I have other sites. My Google custom search button will include things from them....
One of my SheepdogGuides pages.
My site at Arunet.
This page's editor, Tom Boyd, will be pleased if you get in touch by email.
![]() Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org. Mostly passes. There were two "unknown attributes" in Google+ button code, two further "wrong" things in the Google Translate code, and similar in Flattr code. Sigh.
Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org. Mostly passes. There were two "unknown attributes" in Google+ button code, two further "wrong" things in the Google Translate code, and similar in Flattr code. Sigh.