You may find that the database included in LibreOffice or OpenOffice delights you as much as it has me. This page tries to help you use it.
Remember that Libre Office or Open Office, including the database module, is free. Don't let that fool you, though. Big organizations, governmental and civilian, have adopted it as their standard office suite... and saving million$, but still Getting The Job Done. And making things easy for users on different platforms... Linux, Mac, Windows all spoken here!
There's more about Libre Office in the main index to this material. Adabas? Star Office? Ancient history.
This page is "browser friendly". Make your browser window as wide as you want it. The text will flow nicely for you. It is easier to read in a narrow window. With most browsers, pressing plus, minus or zero while the control key (ctrl) is held down will change the texts size. (Enlarge, reduce, restore to default, respectively.) (This is fully explained, and there are more tips, at my Power Browsing page.)
Page contents © TK Boyd, Sheepdog Software, 6/10- 3/25.
This essay will explore how Libre Office can help family history enthusiasts looking into their genealogy.
It is not meant to propose a finished system for actual use. If you want a database for genealogy work, I suggest you pay for a professionally invented, refined and supported tool.
It will, I hope, help you see things about Good Database Design, and about record keeping for family history studies.
It will, I hope, serve as a starting point, from which Libre Office programmers more skilled that I can extend the story.
Beware: You may find yourself disappointed, or even annoyed when you get to the end of this essay. It takes you a long way towards a complete family tree database... but not all the way. I hope to extend it in due course... but it's not all there yet!
More by luck than design, I started recording my family history research efforts with "Kith and Kin", from Spansoft. The fact that it was and is "try before you buy", i.e. shareware, was a major factor leading to my adoption of the program.
This is "try before you buy"... and a SENSIBLE trial, by the way. In June 2010, the software was offered for £38 for Kith and Kin WITH Tree Draw. (For the extra you pay, I'd certainly buy the Tree Draw while you're at it!). The proce 3/2021: £35 the pair! (^_^) (Or £30 for Kith And Kin on its own.)
If "my" design for recording genealogical research results looks very like Spansoft's, I believe it is because it is "the obvious" way to do it. Ford doesn't get upset when Mercedes releases a car with four wheels. Apologies to Spansoft if they think I "stolen" a "proprietary" idea... but isn't there a saying that imitation is the most sincere form of compliment?
You will not build a "copy" of Kith and Kin with the help of this essay. That's why, if you really want to record family history data, that I recommend that you buy a "proper" answer, be it Kith and Kin or another. This essay is meant to build your database design and development skills, and show you some of the features of Libre Office's Base RDBMS.
Whatever package you opt for: Be sure it offers "export to GEDCOM". This is the "lingua franca" for genealogists, and future-proofs your work.
Also be sure to keep meticulous records of where your "facts" come from.
Family tree research is a nice example of how fitting the real world into the finicky world of the computer requires some careful thought.
With ANY database, you need to ask yourself: What information do I have? How should I store it? What do I want to get back from the database?
Except for trivial database tasks, there are alternative ways to do a given job. The alternative ways will each have strengths and weaknesses... and the skilful database developer knows how to go down the road which leads to the answer with the best compromises between the different alternative answers.
Sample Data For Our Discussion
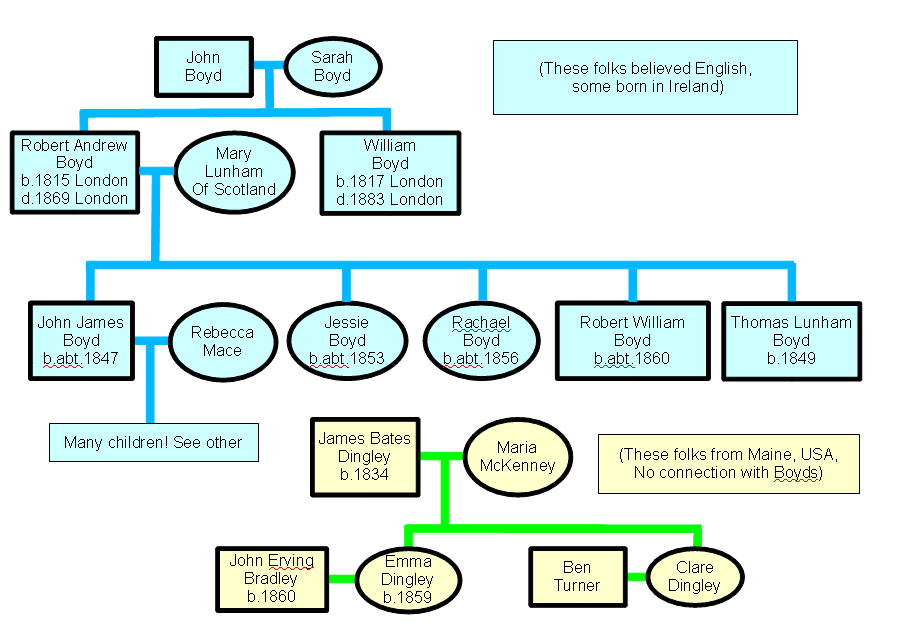
So that we have something to "get our teeth into", here is some real family history. If you can tell me more about any of these people, by the way, they are of interest to me.
We'll come back to the computer side of things in a moment. First we need to talk about things all genealogists have always struggled with... even in the days before computers.
1) Family History data is unreliable and "fuzzy". 20 years ago I "knew" of two Boyds in London, dob 1/1/1820 and 2/2/1818, respectively. Named James and Henry. Five years ago, I leaned that my "two Boyds" were one person: James Henry Boyd, b. 1/1/1818. (Okay, so I made that example up... but that sort of thing happens!)
2) It is essential to have a system in place which allows you to find things in all the notes you have made about people you are (or may be) related to. For example...
What told you that Ebenezer's wife was Ruth? Family bible? Census? What?
... or ...
Percy Seville Boyd? Where did you see that name before? Ah! Percival Boyd. (Say "Percy Seville" quickly) Heck. Not another Percy Seville after all.
If you can accurately hold what you know about your family in your head, you don't know much about them yet!
If you take up family history hunting, you should try from the start to be rigorous about keeping accurate records not just what you know (Uncle John's wife was Mary), but how you know it... They were at your birthday party? You've got a copy of their marriage certificate from the national register? (And if you do: Can you lay your hands on it?)
Try to keep these requirements in mind as we now turn to "pouring everything" into an Libre Office database.
The foundation of any database is its tables.
The rules of normalized table design take some mastering, but, even at my "journeyman" level, I fully embrace the value of those rules and that kind of table, even though I can't yet make them do all I would wish. But! I have some experience of paying the price for bending the rules, and I've not yet found a case where the rules have really made it impossible to do something I wanted to do. Wikipedia has a useful article on normalized table design.
Normalized tables won't have duplicated data, unless you count entries in table "A" of values in table "B" when those entries are merely there to create links records between the two tables. Good table design often helps ensure that your tables don't have unnecessary "empty spaces". (That's one of the things that makes it "good"!)
If the tables in a database each relate to a real "thing" in the real world, they are often easy to "get right".
Enough theory! On to our example.
Remember: We are not trying to make a database which would have everything a genealogist would want... For instance, I won't include a way to record dates of marriage into the database. There WILL be a way to enter dates of birth or Christening. From that, I expect you to be able to see how the database MIGHT be fledged out to a more complete product... but I would still advise you not to do this; buy a "proper" family tree recording suite.
You can download a .obd file called FDB009 with all that this tutorial discusses already set up, and with data... but if you build it with me, as set out in the material below, you'll understand everything better.
First table: "People": The obvious place to start is not necessarily a bad place!
Almost all of our tables, for this exercise, will have "boring" primary key fields. There is no end to the clever things you can... and often should... do when designing the primary key for a table. But we won't explore ideas in that area in this essay. In every table, there will be a primary key field. It will be the first field in the table. Usually, it will be an "autovalue" (auto-incrementing) integer. It will have a simple name like PeoID which stands for "a PEOple's record ID, for the people table." (You might simply call this field "ID" in all of the tables. The computer would cope, but I will give each a different name, ending in ID, to make talking about them easy.)
So.... first field, of the "People" table, the first table we will build: PeoID, data type: integer.
Next two fields: Date of birth or Christening/ Date of Death. "DOBC", "DOD". Data type: Date (Don't get me started on all the issues that little simplification entails! Every time we talk about a date in a database... any database... we are on the brink of a discussion which could fill several books. In addition, the various dates needed in a family history database have a slew of extra, genealogy-specific complications. For now, we'll leave it at that, apart from adding that any dates in the sample data are to be considered as possibly approximate. (If you can help me with, say, the real world Robert Andrew Boyd, but "your" Robert Andrew died in 1867, don't conclude that he's a different Robert Andrew from the one of interest.)
Next two fields: Surname, given names. "Snam", "Gnam". Text. Length 20. So... Bill Clinton's wife would be recorded as Snam= Rodham, Gnam= Hillary. It may surprise you that we don't need to put the married name in the People table. If we NEEDED it, we'd have to make a field, but, for many Western Europeans at least, think about it: Half the time (the men), there wouldn't be a need to enter their surname in two places. And in any case, many people marry more than once. Having fields like "first married name", "second married name", etc. is BAD IDEA. How many such fields would you need to provide to each record, anyway? You'll see that we get around all these problems quite neatly in just a little while.
Like dates, names are the source of many, many woes... which again, I am funking for now.
The last (!) field we need for the "People" table is a "Child of" field. We'll call it "ChdOf", and it will be of type integer. More on this later. (Originally, I was going to call it "CldOf", but if you can avoid ones and "ells" in field names, you won't later have problems because someone reads, say, and ell (l) as a one (1). (Of course, avoiding "ohs" and zeros is another good thing to do, but I failed to come up with a clear name without the "oh".)
One table down!
"Fams" is going to be the name for the next table. The name is short for "families", which won't in every case mean what we generally mean by "family". I apologize if you find that shortening of the name distasteful, but for some of the things we may eventually want to do, short names help us.
How's your history? Did you know (I didn't) that Richard III of England (r.1483-1485), had two children by Katherine Haute, who was not his wife? (The children were John of Gloucester and Katherine, who married William Herbert, 2nd Earl of Pembroke.)
For our purposes, Richard and Katherine Haute will be considered "a family".
By the way, Wikipedia gets full marks for temperance. When I asked it for "famous bastards", Wikipedia asked if I meant "famous last words"? But I digress.
However complicated the affairs of men and women become, I think I'm safe in setting up the database upon a premise that each child will have exactly one (biological) father and exactly one (biological) mother. While much of the world is messy, and not "computer friendly", some things are "tidier". (Surrogacy raises some interesting issues, though!)
I will "digress" again for a moment... but this time with more in mind that just lightening the tone of all this.
I once ran the database for a school, in which the details of our pupils were held. One boy made a difficulty for me by having two dates of birth! (He came from a country ours was at odds with. He flew from home on one passport, birthdate "A", changed planes and passports in a neutral country, and arrived with us on his second passport, birthdate "B". "When first we practise to deceive...", and all that.
Anyway! Back to work!
The "Fams" table needs only three fields:
As "Fath" and "Moth" hold PeoID values, you can, I hope, see that these fields must also be of type integer. (But those fields will not be auto-incrementing, i.e. not "autovalue".)
Now, in a "real" family tree database we would certainly have a "Date of Marriage" field. But as we have enough date fields in our example database already, won't put the "date of marriage" field in.
See something cool? If someone doesn't marry, there's no wasted space. On the other hand, if you want Henry VIII in the database, it can accommodate his 6 weddings without breaking a sweat. If we have details of any children of Henry and women he wasn't married to, they can go in too!
We'll start with some real people, about whom I would like to know more, John and Sarah Boyd, of London, England. They had, at least, two sons: Robert Andrew and William, dates of birth or Christening 1815 and 1817 respectively; died 1869 and 1883. (All of the information you will be given in the text is in the more traditionally drawn family tree that comes with this essay. There may be some information in the database at the end of the exercise which has come from the traditional tree, but didn't get mentioned in the essay.)
Actually, we should set up relationships (using that term in the database sense) before we start entering data. We ought to create a relationship between People.PeoId and Fams.Fath, and we ought to create a relationship between People.PeoId and Fams.Moth. Do that if you know how; struggle with it for Extra Credit, if you don't!
(There's more on relationships and joins in a short(er) page I've done talking about these important concepts in general terms. They are not the same thing, but the differences constantly blur in my mind, and I hope to help you fight that problem.
First we enter John and Sarah in the People table. If you are, as I was, entering them as the first records, they will end up with PeoID 0 and 1. (Computers count from zero.)
The numbers in the PeoID field don't "mean" anything... the are only there so that...
a) Every record in the table has a unique identifier, and
b) We have a way to say "that one", concisely, if we want to specify a single record, which, also as it happens, specifies a single person.
For John and Sarah, and indeed for many people and families, we do not, will not know everything. We won't fill in every field for every record.
The computer, as I tried to explain above, will automatically issue a number for the PeoID field. (Every record must have an entry in this field.)
Other than that, for John and Sarah, we can only make a total of three entries in the People table: Snam and Gnam for John, Gnam for Sarah.
A fancier family history database might let us fill in a guess or approximation for their dates of birth and death, and give us a way to record the basis of our guess, and an indication of limits on it. I'd say, for instance, that as they had a child in 1815, they were probably both born before 1802 (!)... but that is a detail. In this essay, I am trying to paint the broad picture.
Now that we have values in the PeoID field of the People table (that, by the way, can be expressed with "Now that we have People.PeoID values"), we can create a record in the Families table, to pave the way for entering Robert Andrew Boyd's data, complete with the information about who his parents were.
"Fams" table
FamID Fath Moth <-- Fields
0 0 1 <-- Values, first record.That "says": The family we are calling "zero" consists of the man with "zero" in his People.PeoID field, and the woman with "one" in her People.PeoID field.
Now go back to the People table, and enter the details for Robert Andrew and William:
PeoID DOBC DOD Snam Gnam ChdOf
2 1815 1869 Boyd Robert Andrew 0
3 1817 1883 Boyd William 0(Remember: The PeoID numbers are issued by the computer. If I'd entered William, and then Robert, the PeoID for William would have been "2".)
Remember I said that I would NOT get bogged down in "dates" data details? All dates in this demo database will be January 1st of the year the real date was in. This allows us to use "Date" format fields, but saves us certain discussions.
The default display format for a date uses just two digits for the year. Set the display format to show 4 digits. (Yes, I'm "cheating", "being bad" at this point, and working directly with the tables. YOU of course would Be Good, and set up forms, and interact with the tables through the forms. But you don't have this, and other, essays to write! I've created forms for you for the major tables.)
That's (almost!) it! With so little, you can do a great deal! Marvel at the elegance! Don't worry about the difficulties you may be imagining. They could arise from things like trying to simply remember that the number for John and Sarah's liaison is "0". The computer will help us with things like that, but it can only do so because we have things properly, in a good, computer friendly, way. Computer friendly in its internals. We can make the externals human friendly.
I'll take you through adding some more names to the database, just to be sure. Do think as you are doing it... does what you are doing Make Sense? (If not, figure out what you're missing... or write to me and "complain") You have to enter things in the order given, or the PeoIDs and FamIDs won't be as in this essay, and I won't be able to tell you what to put in other places where you enter them by hand later.
Add Robert Andrew's wife Mary to the People table...
PeoID Snam Gnam
4 Lunham Mary
Make an entry for her and Robert Andrew in the Fams table...
FamID Fath Moth
1 2 4
... and now we can enter John James....
PeoID DOBC Snam Gnam
5 1847 Boyd John James
Got it? That's "all" there is it... to the extent that we've developed the database so far. In the downloadable file, you will find the rest of the people shown in the "traditional" family tree, above. They were all entered as above. Nothing new or fancy was needed.
So far, we have a bad database for recording the results of research into family history. We can record people and their biological relationships... important... but we have not made any provision for recording how we know what we know.
The first step in my own quest to "tame" the chaos of all the bits and pieces I've collected about my own family, and about people who might be part of my tree was to decide that everything, somehow or other, would be reduced to individual documents, usually just single sheet of paper. And each would have a unique "name".
That approach brought several advantages. For one thing, I can keep a copy of all my source documents, and if anything happens to my "prime" copy, my work isn't lost.
Sometimes the "source document" will merely be a record of where something can be found, for instance it may say "See chapter 5 of (such and such a book". Other times, my source document is a copy... my prime, definitive copy... of something else, e.g. the family tree in the front of the family bible.
A quick word about the IDs I use on my actual source documents. These details may help you define a good system for your needs. Not because you will exactly adopt my system, but because by studying it you can see some of the traps and some of the answers.
On the document itself, I might write something like "fhs402c03a". The "fhs" stands for "Family History Source (document). For the purposes of a database, within the database we will be able to infer the "fhs" from the context, so we won't need to (and indeed shouldn't) type it in over and over again.
The "4" is present for many, many of my documents... which is an argument for putting it at the right hand end of the identifier, but I have it at the "wrong" end as the best choice between two sets of evils. It comes from "A4", the European designation of paper that is about the size of what people in the US call "letter" sized. Sometimes there's a "5" in that position. There's a "5" when the document is a piece of "A5" sized paper (half a sheet of A4). Those are the only two values I use in that position at the moment, but the system can be expanded as the need arises. That would happen if I found myself collecting source material in other physical formats. Who knows? I may one day get an A2 printer, and will have large sheets of paper to catalog and store. Note that by having this character in the code, I can store all the A4 sized things together, all the A5 sized things together, etc, and (in theory!) never have any trouble in laying my hands on a particular document. (Within their size categories, I simply store them "in order", according to their IDs.)
The next two characters are always digits. They come from the year the document was assigned its ID. Happily, I only started this after 1999, and I don't expect it to be needed beyond 2099, so the "02" in the example says that this document received its ID in 2002.
The month a document ID was created is indicated with a single character. 1,2,3...9 for Jan, February, March .. September. For October, November, December, I use "a" "b", "c" respectively. It seems a little odd at first, but there are significant advantages , and you soon get used to it. The document in the example got its ID... "fhs402c03a"... in December.
The next two... always two... characters are always digits, and come from the day of the month the document was given the ID. Put a leading zero in front of 1,2,3...9. The document in the example got its ID on December ("c") third ("03").
By the way... throughout, I use lower case letters. They're easier for the eye to distinguish, having ascenders and descenders within the data, and I find the shift key a nuisance, not being a skilled typist. As I won't have to type them as often, and for the information which can be passed by the state of the letters, I use mixed case for table and field names, e.g. "People", and "PeoID".
The last character is used sequentially. The first document given an ID on a given day has an "a" at the right hand end, the next is given the "b", then "c", "d"... etc.
WHY NOT.... just use "1" as the whole name for the first document, "2" for the next, "3" for the next... and so on??
Well... you can. But the my system means that you only have to remember what work you have done TODAY to know what the next ID should be! Sometimes I am collecting data in situations where accessing my main records isn't easy.
===
So. We have a pile of documents, and a way to give each of them an ID. For the purposes of FDB009, the database that comes with this tutorial, the database we are "building" here, we are not going to use the ID scheme I have just explained. We're merely going to use a serially issued number, and preface the ID numbers with "sd" to stand for "source document". For the sake of our further discussions, we'll pretend that we have the following documents....
That will do for now. Of course, in a real family history record keeping situation, there would be many, many documents.
This one will be called "Sources". It will be a catalog of the source documents, the sort of document we have just been discussing.
"Sources" will have three fields:
SouID: The primary key for the table, but NOT an integer, NOT assigned to records automatically by the computer. The SouID field in FDB009 is of type "Text", fixed length of 5 (use 6 i f you want the "sd" and you thing you'll go over 1000 source documents!), and holds things like "sd001". As with the "fhs" I use in my actual data recording, the "sd" could be left out of the records in FDB009. I haven't done that in the machine readable copy of FDB009 which is available for download, though, just to make SouIDs easy to recognize anywhere they arise, inside the computer or outside, during our consideration of doing family tree and history recording.
The second field in Sources will be called "T", for "type", and will hold a single character. (Hence the telegraphic name for the field... we don't want to have to make a column for that data 4 times wider than it needs to be, just so we can display the column heading!)
* If Sources.t="b", then the source document is a birth or baptismal certificate. (In the real world, you'd want to give them different codes.)
* If Sources.t="s" the document is a marriage license, defining "Spouses".
* I reserved the "m" code for that most glorious of categories: "Miscellaneous". If you always give yourself a "m" code, you never have to "force" something into a category which isn't really right, a category which is merely "least bad".
Finally, the last field of "Sources" will be called "Desc", for description, and will be set up to hold a short string of text. While it will tempt you to "double enter" some data, as long as you treat Sources.Desc as just a cataloguing aid, you'll be okay. You'd probably put "Robert Andrew Boyd 1815" into the desc field for his birth certificate... AND enter the same information in his record in the People table. You can, actually, skip the entry in the Sources table, if you wish to, for a birth certificate. You'll know WHOSE birth certificate it is by other means, and you'll know that it is a birth certificate from the Sources.t entry. However, not every source document will be so self obvious. The Letter from Aunt Rene, saying in part, "visited John, his wife Sarah and boys Robert and William", is an example of something where the description might be particularly useful. And the system gives you something important along the way: A means of going back, and checking the source, to see if it was interpreted well.
Here are our source documents again, this time with their "T" coding, as well.
If the work the database was covering was a joint project between several people, you would want a field in Sources to establish who had collected the data in that source document.
It may occur to you that some fields might usefully be made "entry required" fields. While some records will be meaningless without data in certain fields, I tend not to set the "entry required" flag. Overuse can make entering data tedious.
Remember when libraries had card catalogs? If so, bear with me for a moment....
Once upon a time, if you went to a library to borrow a copy of Ridley Pearson's 2010 book for young adults, The Academy, you went to the "card catalog". It was a set of drawers filled with small cards, usually 3" x 5". There was a card for "Pearson, Ridley", and a card for "Academy, The". And these cards were filed alphabetically. Each card held the other data, and also an indication of where in the library the book would be found. You could find the "where is it" information either from the "Pearson" card or from the "Academy" card. The first Pearson card you looked at might not be the one you needed, but you would be close to it.
Of course, all of this is usually done (and done well) by computers today. The library computer database has a "books" table, with fields for author, title and location, and forms which give rise to the results of searches for, say, "Pearson" or "Academy".
So far, so good. What the old fashioned, cellulose based card catalog was good at was dealing with exceptions. Suppose someone wanted anyone looking at either card to know that the book had been given to the library by the author. Easy! Just make a note on each card. Computer systems are not nearly so flexible, without extra work. You can't just "add" a non-standard "note" to just some cards. But I said not so flexible without extra work. It is that "extra work" that I am going to describe now, in the context of our family tree data recording case study.
We're going to have one discussion but, arising from it, add three new tables to the database.
===
In the course of our research, we will find out things about People, "Families" and the Sources we have consulted in our research... things that won't "fit" nicely into the fields we have provided in our three tables, our tables for those entities.
No problem! We just create three new tables!! I've called them NotesP, NotesF and NotesS. It doesn't pay to be imaginative when dealing with computers, as the are unimaginative by nature.
Each table will have a primary key field of the simple "meaningless" integer kind. I've called those fields "NpID", "NfID" and "NsID". And each record will have second field called "Note", of type "Memo". Memo fields are great for pouring odds and ends of text into... but have shortcomings in many other ways. While the database we are building for the purposes of discussion only has this simple provision for notes, a "real" family tree database might have provision for two sorts of notes, long notes and short notes. The former would be provided for as we have provided for "notes" in general, and the latter would be similar, but the "Note" field would be of a simple "text" data type.
Have a look at some of the "notes" in the supplied database.
Has a problem occurred to you? It is "How do we match notes up with the person, family or source document they relate to?" Pretty important! Why not just use the ID of the person, etc, as the ID for the note? You could... if...
There was only ever one note per person, etc.
and...
You never wanted to "connect" a given note to more than one person, etc.
The problem does have a solution... three more tables! I've called them NotesPKey, NotesFKey and NotesSKey. I was going to do it as one table, but the difference between the schemes for the primary keys of the Sources records, and those in the other tables got in the way of my "cunning plan". (There were other ways around the problem, but the "three tables" answer seemed best here. Just adding a "this note applies to (id given) record" field would have worked quite well... but it didn't provide for "attaching" a single note to multiple records.)
The three tables are similar, and similar to the "Families" table you have already seen.
Each starts with an auto-incrementing integer, to give the record a primary key.
Then there are two more fields: One for the note, and one for ID of the person, family or source document it deals with.
See the sample database for some instances of the NotesPKey, NotesFKey and NotesSKey in action.
It may seem I've gone "table mad"... and there is one more to go... but by effective use of tables you can bring yourself many advantages. Your database can be smaller. The data in it can have "integrity", in other words things "fit together" properly.
We're going to build a way to see what source documents we have for any particular person or family. You might think we've already got this, but the NotesPKey, NotesFKey and NotesSKey tables merely tell us what NOTES we have for any person, family or source document.
The table name, "ReDocPF", needs a little explanation. It is short for "RElating source DOCuments to People or Families (and vice versa)". This job could, by the way, be done with two tables. It might be more obvious to do it that way, but what I've done shows you a "twist", a variation on what we did before... and it just "feels right". Why have two tables, when a job can be done with one?
The first field holds, as usual, a simple meaningless, autovalue integer to give each record a primary key value. The field is called "ReID", for "RElationships table ID"
Add the following fields after that:
How do we use these fields? What goes in them?
Remember our hypothetical copy of Robert Andrew Boyd's birth certificate? Recall that we gave it "sd001" for an ID for this discussion, eschewing the more complex "fhs402c03a"- type ID code I use in my real world case of this sort of work.
That document would give rise to the following record in ReDocPF
ReID SDID PFID PF
0 sd001 2 p
Hang in there! This may seem "impossible" and "stupid"... but we're nearly "at the top of the mountain", where you will see a thing of wonder and beauty spread out beneath your feet!
The example just given works like this....
The "0" for ReID "just happened". It is the value assigned to the record "by the system".
For SDID, we put sd001 because that is the document we want to enter into the database.
For PFID, we entered 2 because that is the id number for Robert Andrew Boyd (the subject of sd001) in the People table, i.e. his People.PeoID number.
For PF, we entered "p" to indicate that this record reports a Person who is at least a part of the subject matter of sd001.
And that does it! At last! We now have a viable system for holding what we've found about families history, and how we know the things we've discovered. We haven't done much (yet) to make it "user friendly" (whew!), and I'll give another example related to ReDocPF in a moment, but we are DONE creating tables!!
Here's another ReDocPF example. Think back to sd003, the letter which says, in part, "visited John, his wife Sarah and boys Robert and William".
If we trusted that information enough to cause us to put data in our database (that might be something for a note about the source document), then I would add the following entries to the database. First, there would be the entries (which I hope are obvious) (in the People and Families tables) for any of the mentioned people not already present in the tables. Then, not so obviously, we'd add the following...
ReID SDID PFID PF
1 sd003 0 f says: this doc tells us about "family 0" (John+Sarah)
2 sd003 0 p says: this doc tells us about "person 0" (John)
3 sd003 1 p says: this doc tells us about "person 1" (Sarah)
4 sd003 2 p says: this doc tells us about "person 2" (Robert)
5 sd003 3 p says: this doc tells us about "person 3" (William)Now... all spelt out for you like that, it seems like a lot of fuss! But it is a case of the old truism: "Easy to use = hard to explain". By the way: Most of the "neat, tidy" patterns in the numbers in the data are coincidental, just an artifact of how little data there is in the database so far.
With the structure of tables we have created, we can find out many things. And, by means not yet discussed, we can, when using our database, use names instead of all these wretched numbers and codes. So... questions we can ask....
What "Williams" do we know about?
Who in the database was born between 1800 and 1820?
We can ask "How do I know these things?" about any of the data in the table.
Who were Thomas Lunham's parents? siblings? wife/ wives? children?
Not bad!! If only finding the information was as "easy" as building the database to store and to organize it!
Sorry for the abrupt halt. The online copy of the database wasn't in step with all of the above and I went off to fix that, then did another pass through the above, and now I'm closing up shop for the day!
I dislike 'fancy' websites with more concern for a flashy appearance than for good content. For a pretty picture, I can go to an art gallery. Of course, an attractive site WITH content deserves praise... as long as that pretty face doesn't cost download time. In any case....
I am trying to present this material in a format which makes it easy for you to USE it. There are two aspects to that: The way it is split up, and the way it is posted. See the main index to this material for more information about the way it is split up, and the way it is posted.
If you liked this Libre Office tutorial, see the main index for information other help from the same author.
Search this site, SheepdogGuides.com, including Flat-Earth-Academy...
|
What's New at the Site / / Advanced search
This search tool (free to me and to you) is provided by FreeFind.com... whom I've used since 2000. I'm happy with them... obviously!
Unlike the clever Google search engine, FreeFind's merely looks for the words you type, so....
* Spell them properly.
* Don't bother with "How do I get rich?" That will merely return pages with "how", "do", "I"....
Disclosure: FreeFind tells me what people have searched for. It doesn't tell me your personal details. (If someone would "spy" on you, wouldn't they also feel free to lie in a "privacy statement"? Not to say I'm not lying... how can you tell?... but to say "What are privacy statements worth?".
Please also note that I also have other sites, and that the FreeFind search will not include results from them. They each have their own site-specific search buttons.
My "wywtk.com" site...WhatYouWantToKnow
My "skywoof.com" site.
 This is Sky. "skywoof.com" is named for her. (^_^)
This is Sky. "skywoof.com" is named for her. (^_^)
And there are links from those pages to pages here at my SheepdogGuides.com site, and at my Arduserver.com and Flat-Earth-Academy.com sites, which are also controlled by me.
https://www.arunet.co.uk/tkboyd/ My oldest-still-running site*. Have a laugh at some dated material! It may be dated in styling, but not all of the content is obsolete. Much of what was there is also available at https://skywoof.com/aru/index2.htm (*My Compuserve site is, alas, history.)
To email this page's editor, Tom Boyd.... Editor's email address. Suggestions welcomed! Please cite the page's URL, "sheepdogguides.com/fdb/fdb7FamTree.htm".
![]() Page has been tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org. It passes in some important ways, but still needs work to fully meet HTML 5 expectations. (Copy your page's URL to your clipboard before clicking on the icon, so you can easily paste it into the validator when it has loaded.)-->
Page has been tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org. It passes in some important ways, but still needs work to fully meet HTML 5 expectations. (Copy your page's URL to your clipboard before clicking on the icon, so you can easily paste it into the validator when it has loaded.)-->
AND it has been tested with...

![]() Why is there a script or hidden graphic on this page? I have my web-traffic monitored for me by eXTReMe tracker. They offer a free tracker. If you want to try one, check out their site. Neither my webpages nor my programs incorporate spyware, but if the page has Google tools, they also involve scripts. Why do I mention the scripts? Be sure you know all you need to about spyware.
Why is there a script or hidden graphic on this page? I have my web-traffic monitored for me by eXTReMe tracker. They offer a free tracker. If you want to try one, check out their site. Neither my webpages nor my programs incorporate spyware, but if the page has Google tools, they also involve scripts. Why do I mention the scripts? Be sure you know all you need to about spyware.
. . . . . P a g e . . . E n d s . . . . .