This page is "browser friendly". Make your browser window as wide as you want it. The text will flow nicely for you. It is easier to read in a narrow window. With most browsers, pressing plus, minus or zero while the control key (ctrl) is held down will change the texts size. (Enlarge, reduce, restore to default, respectively.) (This is more fully explained, and there's another tip, at my Power Browsing page.)
The style of this tutorial is a little unusual. It doesn't explain "everything" in the application it talks about, it only covers some of the highlights. The tutorial is also unusual in that it rarely if ever quotes the code for doing things. For that, you will have to consult the sourcecode, which, you can download in a .zip archive, along with a compiled copy of the application.
I actually needed an application to do something for me, and while I was writing it, I made some notes which eventually made their way to the web in the form of the page you are reading.
What did I need the computer to do for me?
I wanted to enter a date, a one letter "serial", and a short description of a book. The computer's job was to create "bookplates" (slips, at this stage, really) with the information I'd entered reduced to a standard format and supplemented with a one letter checksum.
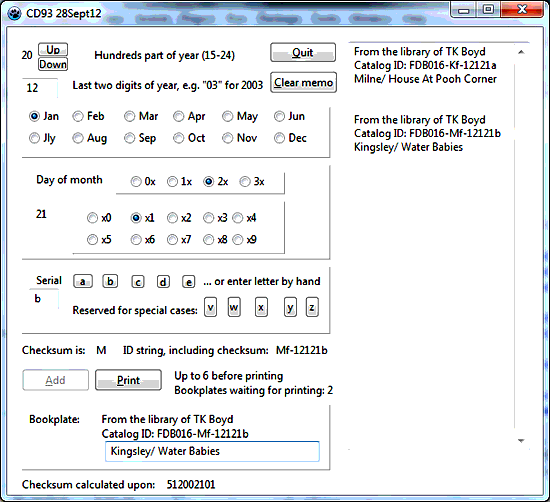
The window in the screenshot may seem complex, but using it is really easy... especially as the date may stay the same for several books, with only the serial needing changing.
The program uses an ini file to keep track of the size and position of the window when the application is closed.
The user can create several "bookplates", and then print them as a batch, on one piece of paper, to be cut up to derive a slip for each book.
The page you are reading now concentrates on how you would create a program, using Lazarus (or Delphi), to help you with the chore of cataloging some items of a collection, cataloging them with a database.
In my tutorials about using the OpenOffice database, I have done a more complete discussion of how the unique identifier was designed.
For a new page discussing easily managed short, computer friendly, unique identifiers, written when I had 8 years more experience in producing this ort of thing, see the page the link takes you to. It is HTML5 friendly, in addition to it's other merits.
Given that you have found your way to this page, you might alos be interested in some work I did in 2020 with creating bookplates with barcodes on them. (There's nothing about the project that particularly ties it to managing books. That work involved further checksums, among other things. (Barcodes often have their own checksums, in addition to the checksums discussed below.)
As I said... the user will enter some data. For my wants, it happens to be about a book, but it could be an instance of another class of object. And the application will generate a short (ish) string of characters which should be satisfactory as a unique identifier for that book. If you know about databases, you will understand what I mean if I tell you that the ID will be the primary key for the book's record in my database describing my collection. If you don't know about databases, you might find them useful, and I can help! I have a series of tutorials to get you started with the wonderful database which is part of the free, multi platform OpenOffice.
Elsewhere, I've written in detail about why I chose the scheme I used for producing the unique identifiers. (A draft is written... when I get THIS essay out the door...)
There is a method in the madness(!). For now, here's what I came up with:
The unique identifier will be a string of seven characters. It will be made up as follows....
... in which L is a letter (a-z, A-Z), D is a digit (0-9), and X is either a letter or a digit. No letter carries an accent. No punctuation marks are used.
The ID may also be described by....
cyymdds
(P.S.: The "c" part will actually usually be a "f".. this is due to a change from defining "a" as 18 to defining it as "15"... a change in the early stages of the programming, but after the bulk of the documentation was done. At this point, the rest of this document reflects the old plan... "c"=20)
Any string of characters can be converted to a string of digits, and a string of digits can be treated as a number. One you have a number, there are easy ways to derive a checksum. So after the application has collected the ingredients for the unique identifier, inside the machine the ID is converted into a number, and from that a checksum is derived. We are now going to go into the details a user is spared.
I also offer a short "basic concepts" note on checksums, if you are interested.
As an example for our checksum calculating exercise, we are going to use "c12a07d"
That, obviously, isn't a number. Do do checksums, life is a lot easier if we have numbers.
Even a string just of digits isn't necessarily, in fact, a number. If I have a three digit combination on my briefcase lock, and it is set to "420", then that's just a string of characters. The fact that 420 is twice 210 is irrelevant... to my needs as the owner of the briefcase. The 420 is just a string of digits.
The string of characters we want to create a checksum for does contain a human-readable information.
The "c12" stands for the year 2012.
The "a" stands for October. (1-9 were used for January to September, but a choice was made to keep the code for the month to one character, hence a, b, c for October, November, December.)
The "07" stands for the seventh day of October 2012.
Don't worry about the "d", just take on board that it is part of the ID string we need to do a checksum for.
The ID string, in the form c12a07d, has its uses. We're going to start our journey the checksum by changing it to something less readable, but more arithmetic friendly:
WHERE DID THAT COME FROM???
c-12-a-07-d
02-12-11-07-03
All we did was to turn any letters into digits, using in every case two digits for each letter.
For the first and last letters, we used: make "a" 00, "b" 01, "c" 02, etc.
If there is a letter in the middle of the string, replace it with 10 if it is "a". 11 if it is "b", 12 if it is "c". If there is a digit in the 4th position in the string, convert it to itself preceded by a zero. (e.g. c12807d would become 0212080703
As we have been promised that only digits and lower case letters will occur, the simple scheme is all that we need.
So! That gives us a string of digits. If we treat them as a number, what is the biggest number which can arise? (as long, as we were also promised, that the biggest letter at the start of the string will never be more than "j")
(Yes... we "count from" 0 when changing the first or terminal letter to a number, 0 for "a", 1 for "b", etc.... hence 25 for "z". the odd coding for the internal letter arises because that character is for a month: "1" for Jan, "2" for Feb... "a" for Oct (10th month, if not counting from zero) "b" for month 11, "c" for month 12.)
All of that may seem very complicated... but remember: All of the tricky bits will be handled by a computer program.
So! "c12a07d" became "0212000703"... which can be treated as a number
And, if you apply the same rules to the unique identifier, and treat the resultant string of digits as a number, and you choose your unique identifier with care, the biggest number you can get is...
.... which, of course, we would usually write as...
Why do I care?
Remember when you were 6 years old, and "the biggest number possible" was an exciting idea?
Computers aren't as clever as six year olds, and can't (easily) just add another zero, trumping...
100000000000 with...
1000000000000
I'm trying to do my checksum work in both the macro language of Open Office's excellent, free, multi platform database, and the free, multi platform Delphi-like language "Lazarus".
Happily, both languages have a data type which can deal with unsigned integers of 6 decimal places... the LongWord type (0 .. 4,294,967,295, four bytes) in the case of Lazarus, and Integer in the case of OpenOffice (all modules). (Integer allows negative 2,147,483,648 to positive 2,147,483,647, OO not having a large unsigned datatype, we'll use this. It is still big enough.)
What was that all about? You do need to look at this sort of thing before you start to write programs. Sorry! (What if your unique identifier had so many characters in it that it resulted in a number that was too big to work in with the usual arithmetic functions of the language you were using? You would get a "Range Check Error". Tedious.)
Whole books have been written on schemes for generating checksums.
A really simple scheme would be as follows...
To create a checksum for "758", you could add the three digits together: 7+5+8: 20. If you wanted just one digit for the checksum, you could use just the units. In other words, "throw away" the "2" of the "20".
A major problem with that too simple answer is that you get the same checksum for "785", which may very well be what some careless person will enter when they try for 758. Sigh.
For my needs, there is something which will catch transpositions, but isn't hard to implement. It is using the "mod" function.
0 mod 3 is 0 1 mod 3 is 1 2 mod 3 is 2 3 mod 3 is 0 4 mod 3 is 1 5 mod 3 is 2 6 mod 3 is 0 7 mod 3 is 1 8 mod 3 is 2 9 mod 3 is 0 10 mod 3 is 1 11 mod 3 is 2 12 mod 3 is 0 13 mod 3 is 1 14 mod 3 is 2 15 mod 3 is 0... etc
The answer to x mod y is always no more than y-1
Now... if we use "mod 3" as the rule for making our checksum, then only three checksums arise: 0, 1 and 2. So, just by (ad) luck, we have a 1 in 3 chance of getting the "right" checksum to the wrong number. The checksum is the same for both 11 and 14. This is always a problem, in principle, with checksums....
But we can make the practice useable... with a bigger "y".
If we were prepared to use a two digit checksum, we could do the number-to-be-checksumed mod 100, and get checksums from 00 to 99. Now there's only a one in a hundred chance of the wrong number having the same checksum as the number we are trying to protect.
But I want it all! I want short unique identifiers (including the checksum) and robust checksums.
The first step is to use a character for the checksum, and treat it as a number. "a" for 00, "b" for 01, etc.... gives us a way to write 0 to 25 as our checksum for the cost of only one character.
And we'll get a little fancier. I want to leave out "oh" and "ell" (o and l), because it is so easy to confuse them for zero and one (0 and 1).
Not a problem. I'll just make a list of the characters I am prepared to use.... and the "value" of a given character will be it's position in the list....
a b c d... j k m n p... 00 01 02 03...09 10 11 12 13
AND, as long as users understand that the checksum character is case sensitive, I can go on....
A B C D... 22 23 24 25...
Why was "A" assigned to 22? Surely it would be 27? Ah! But some of the letters from a-z were left out, weren't they? (Whether in the final program "A" ends up at 22, or at some other number nearby I don't at this stage know or care. I know that I can represent about 50 numbers with a single letter, if case counts, even if I leave out things like "oh" and "ell". WHICH get left out, and how things are done, you can see for yourself by looking inside the program's code.
So that's it, for the essentials of how the checksum will be calculated and represented. The rest of this tutorial addresses issues of user interface.
Let's just be clear about what it is for. Always important, and not just if you are writing a tutorial, like this one. Even if you are the only person involved in the development of a new application, you need to be clear about what is it for long before you do any programming.
When the application is finished, I envision myself sitting down at my desk with some uncatalogued books. I will record some basic data about each on a data capture form... and ink-on-paper first "home" of the data. When... not if... the computer crashes, and I have to rebuild the database, I will have what I need.
For our purposes, we can imagine that the database merely holds each book's unique identifier, author name, title. We'll also explore managing the invoices which go with the books. Each invoice will get a unique identifier, of a slightly different design than that for the book, and the database will hold further various things, tied to that ID. For our purposes just the date on the invoice and the seller's name will give us enough "grist" for our "mill".
If you are new to databases, it may surprise you, but there will be two "tables", two things a bit like spreadsheets. One line per book or invoice (these are the "records"), one column per "thing" we are tracking... ID, title, author, etc. (These are the "fields".) You might think that this implies "two databases". Not at all. Many databases have multiple tables. It will, however, mean two data collection documents, one for the books, one for the invoices.
Why I mention the following will become clear as we go along.
All of my databases have unique identifiers. More recent ones are in the form "FDBxxx" where FDB stands for FreeDataBase, for the database which is part of Open Office, and xxx is a three digit serial number. I have a sheet of paper telling me that FDB001 holds my friends' birthdays, and FDB015 is a database of books I've read, etc. The FDB index for my book collection is 016
While I'm actually working within a given database, I don't have to continually repeat the appropriate "FDBxxx"... it is implied. When I do use it will become clear...
I'd start a data entry session by recording the first invoice. I'd create a new line on the "Invoices" table's data collection document. An ID would be created for the invoice, and that and the invoice date and the seller's name would be recorded, "merely" handwritten paper, for now. The database's ID for the invoice would be written on it, prefixed "FDB016". Anyone with just the invoice in their hand deserves some help with what the string of characters in the upper corner is about.
Next I would turn to the first book listed on that invoice. I would make up an ID for the book, according to the rules discussed elsewhere. On the "Books" data collection form, the book's unique identifier, apart from the checksum, would be entered. A blank-for-now column would exist for the checksum. The author's name and the book's title would be entered. And the database's unique identifier for the relevant invoice.
... and then I would do the same for the rest of the books on that invoice, then process the next invoice and its books, and so on until all the books and invoices to be processed have been entered on the pencil-or-ink-on-paper data collection sheets.
And we haven't yet touched the computer! Whew! Good!
Now, alas, we do have to turn the computer on.
I'd bring up the database, filling most of my screen, and CD93 (the application this essay is about!) in a corner of the screen.
I'd then start entering the data from the data collection sheets into the computer. More on the details of that in a moment.
As I came to each book, I would enter the relevant details into CD93, which would give me the right checksum for them, along with the unique identifier in precisely the right form... leading zeros not omitted. "November" coded as "b", etc.
I'd write the checksum in on the data collection sheet, in case it was needed later. I would either write (pencil!) the book's unique identifier, with checksum, in the book, or get the computer to print it on a slip of paper to be put with the book. The ID would be prefixed "FDB016". You find all sorts of things written in the flyleaves of books... The "FDB016" should be a help to recognizing the right string of characters for tying the book to the information about it in the database.
That's it! That's the overview of the heart of my book collection cataloguing system.
Now for a few details of the ID/ checksum generating program.
A lesson in program design: All of the text above was pretty well finished before I started "writing the program", i.e. before I turned Lazarus on and put the first button on the form which would grow into CD93. In place of the screenshot you see below, I inserted a placeholder. And, not until then, I did a sketch, ink-on-paper, of what the screen would look like. Did all of that take time? Of course! Did the text flow from the brow of Zeus, or Minerva, or whoever, right first time? Of course not. But, to revise elements of the above was really quite simple. I considered various formats for the unique identifier, in particular... and each time I changed my plan for how to do it, parts of the text had to be altered. But making those alterations was a lot easier than making changes in a growing program. And the text will serve as my documentation for What The Application Does, essential documentation which I would have needed to write alongside writing the program, if I were not doing this tutorial.
Plan first. In the sort of detail you see above.
Believe it or not, I've left out of what you see above many elements of my planning! (There could be more???) Things that I know I can carry in my head about how I am going to do things. Unless I've made a bad mistake, I do know what I am going to do, and that I know how to do that. Any doubts in those areas? Get the "whats" and the "hows" written down in your documentation. Sometimes it will pay you to do a little "test" program, just to check that one of the things you want to do can be done. If you were new to the "mod" ("modulo") function, which is going to be at the heart of the checksum, you might want to do a little program which would let you put in some "x"s and "y"s and see what the computer gives you for "x mod y".)
A human enters the necessary data. The ID field is filled in by the computer. It will hold "Invalid" if anything in the data is amiss. (It is hard, but not impossible to put invalid data in. For instance, if you say the book was acquired on the 30th of February, the ID field will display "Invalid".)
At any time there is valid data in the form, a checksum for that data will appear in the "checksum" box, a place that only the computer can write to.
Many data are entered by clicking radio buttons, for instance the month of acquisition.
When all of the data for a given book has been entered, the user will copy, by hand, from the screen to the ink-on-paper data collection form the checksum for that data.
Users availing themselves of the hardcopy option will click the "Add" button, which will add that book's ID string to the document being prepared in the computer. Eventually, I hope that this "document" may consist of nice bookplates, one per book, of course. In the early days, the document will consist of many lines, with broad vertical gaps, one line per book.
When done... or when worried about losing accumulated work!... the user will click the "Print" button, and the document(s) accumulated so far will be printed out.
The "Add"/"Print" complications arise because of our "modern" "page oriented" printers. "When I was a boy", it was no hassle to generate a document a line or five at a time. The first book's insert could be printed at the top of the first page, then the second books data entered, and then that book's insert printed on the next part of the same sheet, and so on. But that would be too simple, I suppose. (To be fair... it also imposed significant limitations on what we could do!)
Whew! That's it, I think! AT LAST I can turn to the fun stuff.... writing the program. (Which I did! Almost all of the text above was written before I turned on my Lazarus. But I haven't recounted the blow by blow events of the "bottom up development" here as I normally do in a tutorial. Sorry.)
We've talked extensively about what CD93 does. Here follow some notes on how the programming accomplishes those functions.
-----------
It may be counterintuitive, and not the way we, as humans would do the job, but the program will continually re-calculate the checksum, doing it again and again, every time even one character of one of the ingredients of the ID string changes. In some cases we will use the "hidden" path of the event handler for a change in the control. Elsewhere, we will just call the procedure "UpdateIDString" "by hand".
For the sake of understanding the whole process, we will look at tow of the "ingredients" of the process.
The first ingredient is the "Century" box, laCentury, which continually reflects the contents of bCentury. Because of the way the program is written, it is (should be, anyway!) impossible to assign an invalid value to bCentury. It can only be changed by clicking an "Up" button or a "Down" button, and the program just ignores you if you try to go outside the valid range.
The second ingredient is the edit box, eLSDYear, which should hold two characters, and show something between 00 and 99. However, being an edit box, users can type anything into it, even if our program can rapidly "erase" unwelcome entries.
--------
Besides the various obvious things on the screen, the program also maintains a set of boolean variables for any ingredient of the ID string and checksum which can ever get into an invalid state, for instance the value in eLSDYear.text. Those booleans are set to true if there is a current valid value for the ingredient, to false otherwise.
A procedure called "UpDateIDString" will be called, every time that what is in an ingredient of the ID string is changed. It will generally recompose the unique identifier and attach the right checksum. However, at the start of the code within UpDateIDString, a test is made to see if any of the booleans hold "false", in which case UpDateIDString merely...
Oh yes... I forgot to mention!...
Each time a new ID string is generated, it is copied to the clipboard, as if I had selected the string, by hand, and pressed ctrl-C. (Or used any of the other "copy" triggers.) Because the application has this feature, you can easily use "paste" to fill in the appropriate field over on the database data entry screen.
Making the application do that is trivial, the details are in my tutorial on programmatic "copy to clipboard"; "paste from clipboard".
"All" I had to do was design the program well in the first place, and then find the right place to insert something like "copy it to clipboard"... and provide the necessary infrastructure for the "copy... to clipboard".
Search the sourcecode for "Copy CS+ ID to clipboard", and you'll find the one line that was "all" (apart from infrastructure) that was needed to supply my want. Whew.
The line of code I inserted was...
Clipboard.AsText:=(sCheckSum+sIDString);
Working from the "inside" out....
What was provided by "sCheckSum+sIDString" in this case can be replaced by whatever text you want to send to the clipboard, either as literals...
Clipboard.AsText:=('Send these words');
... or using variables. No rocket science there.
The "AsText" is the name of a property of the Clipboard object. Again... this may be a new property to you, but it is no more "strange" than, say, the "caption" property of a label.
Things do get strange when it comes to the object, "Clipboard". Usually, we declare instances of types, e.g. we create an edit box called "eDay", of the type "TEdit".
For working with the system's clipboard, things are done just a little differently.
First, you add "ClipBrd" to the project's "uses" clause.... and then you are done! And you have, whenever you want to use it, an object named "Clipboard", with an AsText property that you can assign things to. Execute "Clipboard.AsText:='Fred';", and immediately, anything in the system clipboard is replaced with "Fred".
It is only confusing because it is similar to other things, but different. It is like using an edit box, and "playing" with what various properties are set to. However, it is different in that you can only have one "Clipboard", and that is the name of the instance of the type of object. And you don't have to "set up" the "Clipboard" object. It is just there. But you can't use a different name for it. Simple... really... even if it doesn't sit well until you've slept on it. Sigh.
Maybe this will help, not only your grasp of "Clipboard", but perhaps also with figuring out how the printing code works: The "Clipboard" object is a bit like the "Printer" object used within the program. Both are mostly ordinary objects. They are a little strange in where they come from.
End of "blow- by- blow"!
===But I haven't forgotten to create the .zip you can download with the application and sourcecode!
|
|
If you visit 1&1's site from here, it helps me. They host my website, and I wouldn't put this link up for them if I wasn't happy with their service. They offer things for the beginner and the corporation.![]()
![]() Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org. Mostly passes. There were two "unknown attributes" in Google+ button code. Sigh.
Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org. Mostly passes. There were two "unknown attributes" in Google+ button code. Sigh.
....... P a g e . . . E n d s .....